
#5 : No-code tools, Langchain Agent, and Multimodal AI 🙌
Build a Langchain agent using Flowise and Bubble (No-code), What is Multimodal AI ?

Welcome to the episode 5 of AI Tribe 1-1-1 : A Biweekly newsletter designed to spark your interest in AI tools, concepts, applications and research !
This episode covers Multimodal AI in detail and tutorial on Building a No-code Langchain agent using Flowise and Bubble.
So let’s jump straight in !
⚙️ Tool - OpenChat
An open-source chatbot console. Run and create custom ChatGPT-like bots with OpenChat, embed and share these bots anywhere.
It allows users to incorporate it into their websites or applications for various purposes.
😇 Today’s Recipe : Build a Langchain agent using Bubble and Flowise !
Let's build a LangChain agent in under 30 minutes that can access the internet, chat with a PDF, and help us understand code. All without a single line of code using Flowise and bubble.
Reminder : I have already covered Langchain in my previous post so check it out if you haven’t already.
Agents in LangChain Library are helpers that have access to memory, tools, and can assist in problem-solving.
This agent will have access to 3 tools and a memory as shown.

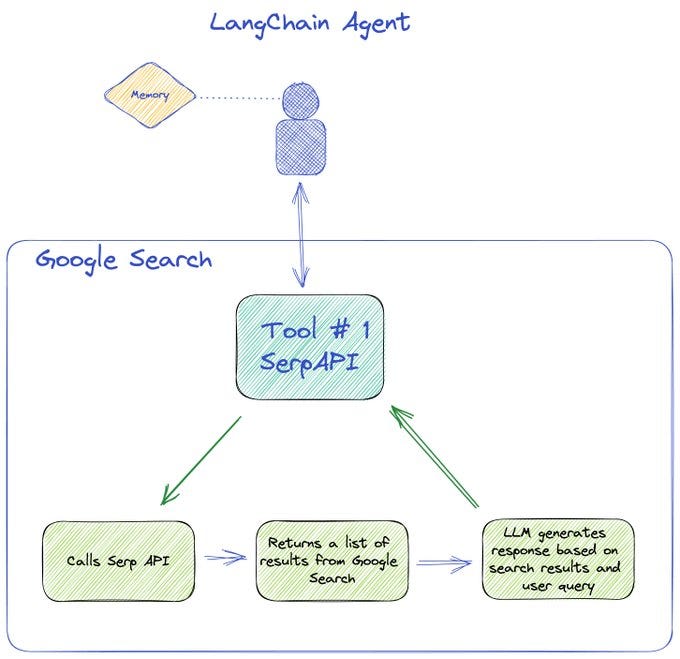
We start with a conversational agent and connect it to the serpAPI tool available in LangChain to perform a Google search. This returns a list of search results, that is then passed to the LLM to generate an answer based on the results and the user query.
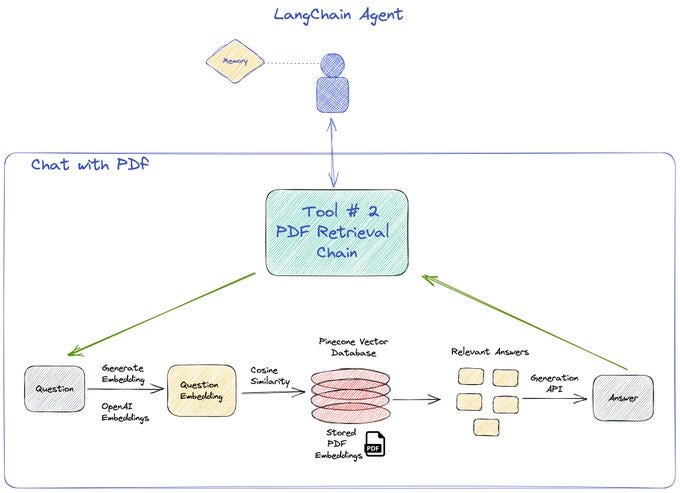
Second tool used is the retrieval QA chain. We first embed a pdf using a PDFloader and save it in pinecone. Our tool then finds the most relevant answer using the OP stack ( OpenAI x pinecone )
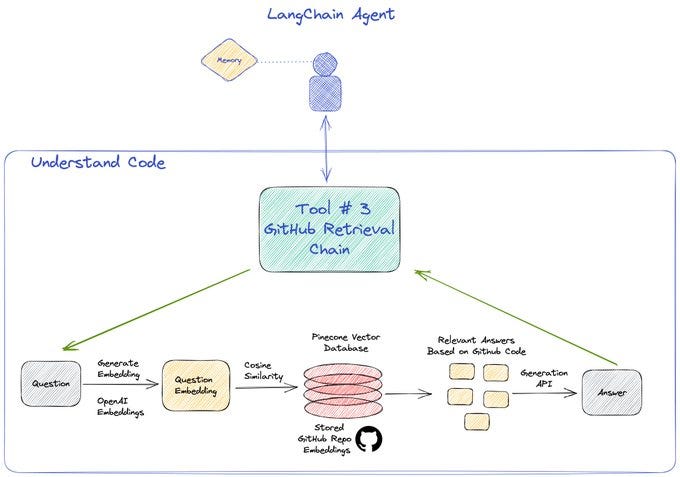
Third tool used is the again the retrieval QA chain but using the GitHub loader for embedding a GitHub repo and then querying it using the OP stack.

Detailed walkthrough with step-by-step instructions at
P.S : Refer a friend and unlock exclusive offers waiting for you !
🔗Article : What is Multimodal AI and how it works ?
Multimodal AI is a type of artificial intelligence that can process and understand information from multiple sources. This includes text, images, audio, and video. Multimodal AI is still in its early stages of development, but it has the potential to revolutionize the way we interact with computers.
For instance, Microsoft Research presented Composable Diffusion (CoDi), a novel generative model capable of generating any combination of output modalities, such as language, image, video, or audio, from any combination of input modalities.
Google’s ChatGPT alternative, Bard got several updates this week, including the multimodal capability and google lens integration. So bard can now analyze and respond to the content of the picture! Just upload a image and prompt an action like “Perform ocr and extract text from this invoice” , “describe this image” or something like I did here → thread on threads ! 😎
How Multimodal AI works ?
Multimodal AI systems are structured around three basic elements: an input module, a fusion module, and an output module.
The input module is a set of neural networks that can take in and process more than one data type. Because each type of data is handled by its own separate neural network, every multimodal AI input module consists of numerous unimodal neural networks.
The fusion module is responsible for integrating and processing pertinent data from each data type and taking advantage of the strengths of each data type.
The output module generates outputs that contribute to the overall understanding of the data. It is responsible for creating the output from the multimodal AI.
More here 👇